








Table of Contents
dbt and databricks regularly prove a potent combination of SQL transformation tools for the Spark warehouse. Add in the advantages of Delta Lake tables like the atomicity of write, and the “3D” combination of dbt, databricks and Delta emerges as a robust tool for data engineering and a core part of a modern data stack.
The 3D synergy allowed us at Explorium to make a huge technological transformation, one that any data discovery organization eventually must undertake to prove its scalability. Our data engineers now build frameworks, not pipelines.
As your data team grows, the value of labor separation becomes clear and the need for data engineers decreases.
Data product developers and analysts hold the domain expertise. They live and breathe specific data sets, and build the transformation logic using SQL. The data engineer’s role becomes somewhat orthogonal to the pipeline. The main responsibilities are providing a simple, little to no code, standardized approach to building ETLs; ensuring data quality and freshness; and building the organization’s ability to monitor the pipelines, data lineage and data catalog.
This article will talk mostly about the data transformation part. Specifically, we will showcase how the responsibility separation framework allows you to glue together different parts of the organization.
Explorium went through a long period when a software engineering team developed a Python library, Entity Transformer. This library is a part of our Explorium Data Model library. As global as it sounds, those transformers are part of a larger software project, ensuring complex validations of what an entity is and how each data record may fit into our vast knowledge graph.
As a more concrete example for a transformer, we use libpostal, a C library for parsing and normalizing street addresses around the world using statistical NLP. Wrapping a library like libpostal in our Python library could, of course, be a PySpark job. However, then we would need to configure the machine environment with a C library preinstallation. We would need to do this for each developer. Then, don’t forget that dbt cannot register python UDFs, let alone the no-code SQL-only standardized approach.
So how could we transform the huge Python project power into an automatic no-code ETL infrastructure? That is, what can we do to make all those transformers available as SQL functions in all of our dbt projects?
Building for frameworks for dbt
Let’s review the dbt project development process and the UDF registration options at our disposal. For this article we’ll be talking only about dbt-core with its extensions and not dbt-cloud.
dbt-spark or dbt-databricks are Python libraries that we can use as a CLI tool to start developing the project on our local machines. We configure it to use sql-endpoint or cluster to run or debug on your local machine. Here are two profiles used for SQL and cluster, respectively:
outputs:
dev:
host: *.cloud.databricks.com
http_path: /sql/1.0/endpoints/***
schema: hive_metastore.silver_dev
threads: 4
token: ***
type: databricks
target: dev
outputs:
dev:
host: ***.cloud.databricks.com
http_path: sql/protocolv1/o/***
schema: silver_dev
threads: 4
token: ***
type: databricks
target: devBecause SQL endpoints use Unity Catalog, you will have to specify Hive_metastore.prefix each time you access your Hive tables. We work with AWS Glue, and silver_dev is one of Glue’s “databases.”
After that, assuming you have dbt-databricks installed, you can run:
dbt run --profiles-dir profiles_dir --profile sql-serverlessor
dbt run --profiles-dir profiles_dir --profile clusterThe first option is much more responsive since there’s no cluster startup time.
Now let’s suppose we want to use Spark UDFs in our models. One of the options would be to implement them in Scala / Java. For example, UDF for calculating h3:
package ai.explorium.dbtUdfs
object GeoUdfs {
val h3Core = H3Core.newInstance()
val h3ify: (Double, Double, Int) => String = (lat, lon, res) => h3Core.geoToH3Address(lat, lon, res)
val h3Udf = F.udf(h3ify)
}
class ExploriumUDFRegistrator extends (SparkSessionExtensions => Unit){
private val LOG = Logger.getLogger(this.getClass)
override def apply(sparkExt: SparkSessionExtensions) {
sparkExt.injectCheckRule((spark => {
LOG.info("Registering UDFs")
spark.udf.register("H3_UDF", GeoUdfs.h3Udf)
(_: LogicalPlan) => Unit
}))
}
}After building the h3_udf.jar we need to make sure it will be loaded into the cluster’s jars directory on startup . We can take care of that with the following init script:
#!/bin/bash
cp /dbfs/tmp/h3_udf.jar /databricks/jars/h3_udf.jarWe also need to add the following Spark config to the cluster:
spark.sql.extensions ai.explorium.dbtUdfs.ExploriumUDFRegistrator After doing that, we will have h3_udf:
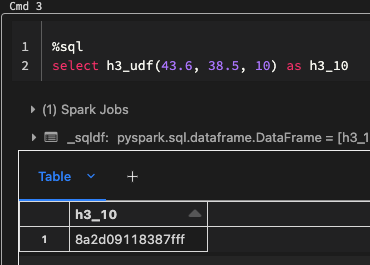
The most exciting part is that the local dbt CLI that connects to this cluster will be able to use this UDF as well. That happens for every Spark context on this cluster since it’s Hive UDF. However, in Python there’s no way to register Hive UDFs on databricks cluster. This means that if your company has a big Python project and we want to use its functionality as SQL UDFs, we will have to register them as Spark UDFs:
spark.udf.register("my_udf", my_python_func, StringType())This code will run on a Spark context and will make my_udf available on this context only. The UDF will not be recognized by any dbt project connecting to the cluster. Given those limitations, we suggest a three-part solution:
- Using a local Spark context in the dbt profile while leveraging the fact that the Spark session is shared between tasks of the same databricks job.
- Handling special C libraries installations with the custom docker image.
- Software patterns for UDF registration.
Using the local Spark context in a dbt profile
In order for the databricks job to use the same Spark context it runs on, we will use the following dbt profile.
target: dev
outputs:
dev:
type: spark
method: session
host: localhost
threads: 2
schema: silver_devFor the dbt commands execution, we will use dbt python SDK:
import dbt.main
from dbt.logger import log_manager
dbt.main.handle_and_check(['run', '--profiles-dir',
'.', '--profile', 'my_dbt_profile'])
log_manager._file_handler.reset()The above code could be executed as a Python task or just in a notebook.

If a previous Python task of the same databricks job registered some PySpark UDFs, they will be available for the above dbt project execution.
Avid databricks users know that there’s a dbt-task available in databricks, but we’ve found this feature to be insufficiently supported and too unstable for production.
Handling special C libraries and other installations
There are a few ways we can install dbt, but the one that suits our purposes best provides a Bootstrap script for the cluster:
#!/bin/bash -xe
sudo apt-get update
apt-get install libffi-dev # resolving dbt dependency hell
/databricks/python/bin/pip install dbt-core==1.2.*
/databricks/python/bin/pip install dbt-spark==1.2.*We use the custom container for the special libraries. For example:
FROM databricksruntime/standard:9.x
...
RUN cd /usr/local && curl -sL https://github.com/openvenues/libpostal/arcHive/refs/tags/v1.1.tar.gz | tar -xz
...Later, after you push your custom image to ECR or another hub, specify the following setting in your cluster definition:
"docker_image": {
"url": "***.dkr.ecr.eu-west-1.amazonaws.com/udf:latest"
}Now you can run spark.udf.register statements in the register_python_udf task and have your special address resolution UDFs available. But let’s see how can we generalize this simple databricks job to serve as the infra for our team to register any UDF and run any dbt command on any dbt project.
Software patterns for udf registration
The existing Python project we’re using for transformations defines the base class like this:

Then every concrete class implements its own transformation:

Another important thing is that all the transformers are listed in __all__ variable in the __init.py__ file of the transformer package.
Recall what we need to know about the transformer in order to register it as UDF . spark.udf.register has three parameters:
UDF name
We can get a snake case name directly from the class instance:

Callable
For convenience, we always return the following structure for every UDF we register, where spark_type is the callable return type.
![]()
We can consider using something like this high-order function to get this callable:

Return type (spark_type)
This may be the most involved step if your transformer returns a complex non-serializable object. You may have to implement your own “Python-to-Spark type” logic, as we did. For simple cases, you may consider using the _parse_datatype_string function.
Eventually, our user will supply us their Python package with their transformers, implemented accordingly to the above pattern. Our job is to install this package and register all the transformers listed in __all__:

Breaking down this code line-by-line
import importlib : We need the ability to implement a generic import logic since our code receives package name as a parameter and then uses the same package.
importlib.import_module(args.get(“udf_catalog_package_path”)) : udf_catalog_package_path is the path to the transformers module withing the package. As an example, the user supplies their package, called explorium_transformation. The transformers themselves (transformers directory module) and __init.py__ are inside the explorium_transformation module:
explorium_transformation\
transformers\
__init.py__
my_tranformer.py
...In this case, the udf_catalog_package_path is explorium_transformation.transformers. Then we take the list of all the transformers, transformers_module.all.
getattr(transformers_module, <transformer class name>) gets classes from the module. Next, we can combine all the functionalities from the above and simply register all the UDFs:

Now all the transformers from the supplied package are available.
In upcoming articles we will go into greater depth to explore how Explorium’s data infrastructure solutions integrate this process. But until then, here’s a quick overview of the architecture that integrates the above functionality:

Backend on AWS Lambda creates databricks jobs
In order to run a dbt project in production, our user utilizes a CLI tool that expects him to fill and submit a JSON file:
{
"dbt_git_url": "https://github.com/explorium-ai/anton-dbt",
"dbt_git_branch": "main",
"udf_catalog_git_branch": "main",
"udf_catalog_git_url": "https://github.com/my-transformers",
"udf_catalog_package_path": "geo.address_transformers"
}The user specifies where their dbt project resides on GitHub, and where the Python transformer package and the actual transformer module are within the package. Those parameters are enough to execute all the registration logic we’ve described above.
So far we’ve performed an overview of the industrial demand to provide automated data infrastructure; seen the need to migrate the functionality of large Python projects into SQL and leverage its expressive power with dbt; and provided a technical and architectural solution to run those projects in production.
A lot of interesting questions remain.
- How to conveniently develop and debug a UDF using dbt project? We’ve seen that local dbt CLI will still not have UDFs registered.
- How to orchestrate a transformation dbt project job with the extraction and load jobs?
- How to integrate data lineage, data quality and freshness assurance?
- On which level – dbt project or infra – should we address challenges like job idempotency and backfilling?
- How to make PySpark UDFs not so horrendously slow?
We’ll tackle those and many more data challenges in future articles.








