








Table of Contents
What is Feature Engineering?
Feature engineering is the process of improving a model’s accuracy by using domain knowledge to select and transform raw data’s most relevant variables into features of predictive models that better represent the underlying problem. Feature engineering and selection aim to improve the way statistical models and machine learning (ML) algorithms perform.
The preprocessing steps that transform raw data into features make up the feature engineering pipeline. These features are used in predictive models and other machine learning algorithms. Predictive models comprise an outcome variable and one or more predictor variables. The feature engineering process is what creates, analyzes, refines, and selects the predictor variables that will be most useful to the predictive model. Some machine learning software offers automated feature engineering.
Feature engineering in machine learning includes four main steps: feature creation, transformation, feature extraction, and feature selection. During these steps, the goal is to create and select features or variables that will achieve the most accurate ML algorithm.
What is Feature Creation?
Feature creation, sometimes just called feature engineering, is the process of training a machine learning model by using existing data to construct new features.
What is Transformation in the Machine Learning Process?
Feature transformation is the process of retaining meaning while modifying data to make ML algorithms more functional and easier to understand, delivering better results.
What is Feature Extraction?
Feature extraction involves extracting and creating new variables automatically from raw data. The goal of feature extraction is to reduce data volume to a more manageable modeling set automatically. Some feature extraction techniques include cluster analysis, edge detection algorithms, principal components analysis, and text analytics.
Feature extraction is used when predictive modeling algorithms cannot directly model observations because they are too voluminous in their raw state. For example, audio, image, tabular, and textual data may have millions of attributes. While supervised learning algorithms may not be effective for this unstructured data, unsupervised learning can be very useful.
Feature extraction creates features from the existing ones and then discards the original features to reduce the total number of features in a dataset. The new, reduced set of features can summarize the original set of features and the information they contain. The newer, smaller dataset can much more easily be modeled.
For tabular data, feature extraction methods might include unsupervised clustering methods and projection methods such as principal component analysis. For image data, techniques might include edge or line detection. All feature extraction methods solve for the issue of dimensional data that is unmanageably high and work automatically.
What is Feature Selection?
During predictive model development, feature selection is the process of selectively reducing the number of input variables. This is always desirable to reduce the computational costs of modeling, and it often enhances model performance.
Features are sometimes more or less important to model accuracy, or may lose relevance in the context of other features. Feature selection algorithms analyze features for relevance and functionality, use a scoring method to rank the features, and determine which features are most useful and deserve to be prioritized and which should be removed for redundancy.
More advanced feature selection techniques may use trial and error to search subsets of features, automatically creating and evaluating models to randomly determine which sub-group of features is objectively the most predictive. Some modeling methods include feature selection as part of their function, such as stepwise regression, an algorithm that includes feature selection in the process of model construction. Ridge regression and LASSO are also algorithms that actively include feature selection as part of the process of building models.
Why is Feature Engineering Important?
Feature engineering for machine learning models is crucial because the results you are able to achieve with a predictive model are directly influenced by the features in your data. And while you can achieve better results with better features, this is not the whole story, either.
Machine learning models are complex and reliant on many interdependent factors. The possible results you achieve with them rely upon the framing of the problem, the model itself, the quality and quantity of available data, and the selected and prepared features. The best features accurately describe inherent structures in the data.
Feature engineering allows you to choose more optimal features. This in turn achieves flexibility. Even a model that is less than optimal can offer good results if it can detect good structure in data. Better features provide more flexibility and enable the use of faster, simpler, less complex models that are easier to maintain.
Well-engineered features mean that simpler models which are not optimal—running the “wrong” parameters, in other words—can still produce functional results.
Why is Feature Engineering so Difficult?
It requires deep technical skills and detailed knowledge of the way each machine learning algorithm works. Successful artificial intelligence (AI) relies on model diversity, so it is essential to train multiple algorithms—each potentially requiring different feature engineering techniques—on the data.
It often demands skill with coding, databases, and programming. Testing the impact of newly created features involves repetitive, trial and error work, and sometimes reveals frustrating insights—for example, that the accuracy worsened rather than improved after more features were added.
Domain expertise—an understanding of how the data and the industry interact—is also critical. For example, in situations where one product has multiple names, it is important to know which products are really the same and should be grouped together for the algorithm to treat them the same.
Ideally, aim to reserve processing power for detecting unobserved patterns in data. Do this by applying domain knowledge to “teach” the algorithm everything that the human team already knows. The ability to achieve this, however, and even to perceive what is “known” on the human side takes experience and skill.
For all of these reasons, feature engineering is time-consuming and resource-intensive. It can take years to gain both the domain knowledge and the technical skills best-practice feature engineering demands. Applying both skill sets within the context of a large data science project can take a few people who possess them years, because of the nature of the trial and error process.

What is Feature Engineering Automation?
Feature engineering for machine learning might include: identifying new sources of data, applying new business rules, or reshaping data. Typically, this is an extended manual process that relies heavily on expertise, manipulation of data, intuition, and domain knowledge. The tedium and resource-intensive nature of the process can limit the final features—as can mere human subjectivity.
Automating this process creates many hundreds or even thousands of candidate features automatically from a dataset. The data scientist can then select the best options and use them for training data.
Automated feature engineering is in no position to replace data scientists – its main strength lies in reshaping data.
In this way, it allows data scientists to engage more with tasks that demand experience, creativity, and business domain feature knowledge. Automating feature engineering allows data scientists to focus on delivering robust models into production, interpreting complex data, creative feature engineering, and other more valuable parts of the machine learning pipeline.
How to Automate Feature Engineering for Machine Learning and Data Analytics
Any process that is tedious, time-consuming, and repetitive is a likely automation candidate. Feature engineering involves analyzing the complex relationships between multiple data sources and automatically generating many candidate variables across a broad range of datasets. Ideally, to increase the predictive power, an automated feature engineering platform will test and rank the candidate features for users. There are various types of feature engineering methods.
Some best practice automated feature engineering techniques include:
Text analysis and NLP. By analyzing plain text, a machine learning platform can glean insights into sentiment analysis, text summary and subject, and more to build features.
Feature engineering for time series data. This type of feature generation analyzes on a sliding window and extracts features such as trend change points, seasonality, and impact from holidays.
Geospatial. This type of analysis considers the curvature of the Earth; how longitude and latitude coordinates relate to other data points; local property attributes; and population density.
Feature engineering for clustering. Data scientists use these kinds of algorithms, such as K-Means, DBSCAN, and other unsupervised ML techniques, to engineer high-level features from raw data.
One hot encoding. One hot encoding feature engineering involves replacing categorical variables with various boolean variables, also called binary variables or dummy variables.
Steps in Feature Engineering
Although not every data scientist does feature engineering the same way, for most machine learning algorithms, the steps for how to perform feature engineering include the following:
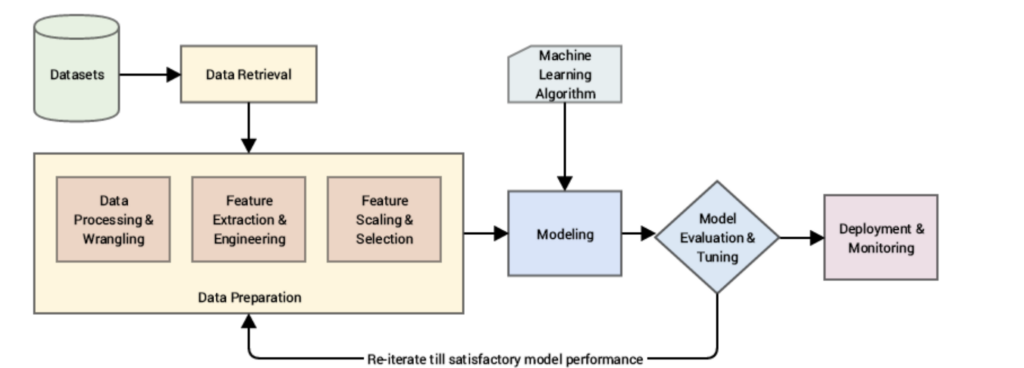
Data Preparation. During data preparation for machine learning, the data scientist consolidates and manipulates the raw data collected from different sources. Eventually the raw data will need to be formatted in a standardized way so that it can be used in a model. Data preparation can include data cleaning, augmentation, fusion, delivery, ingestion, and loading.
Exploratory Analysis. Also called data exploration, in this process the data scientist explores and investigates the data set to identify, analyze, and summarize its main characteristics. Data visualizations are a critical tool for data science experts to better determine how to best manipulate data sources, select the appropriate statistical techniques for data analysis, and choose the optimal model features.
Benchmarking. In this part of the process, the data scientist sets a baseline standard for accuracy. All variables can be compared with this standard to improve the predictability of the model by reducing the rate of error. Business users and data scientists with domain expertise perform testing, experimentation, and optimizing metrics for benchmarking.
The Steps for Data Processing
Data Preprocessing vs Feature Engineering
This is a somewhat confusing distinction on its face, but a closer look at the whole process clarifies the distinctions between data wrangling, data preprocessing, and feature engineering.
The typical pipeline for building an analytic machine learning model looks like this:
- Data access
- Data preprocessing
- Exploratory data analysis (EDA)
- Model building
- Model validation
- Model execution
- Deployment
Data is rarely harvested in usable form. It usually lacks context or a workable structure, and is often riddled with omissions and errors. The data preprocessing in step 2 focuses on the data work necessary before the analytic model is built.
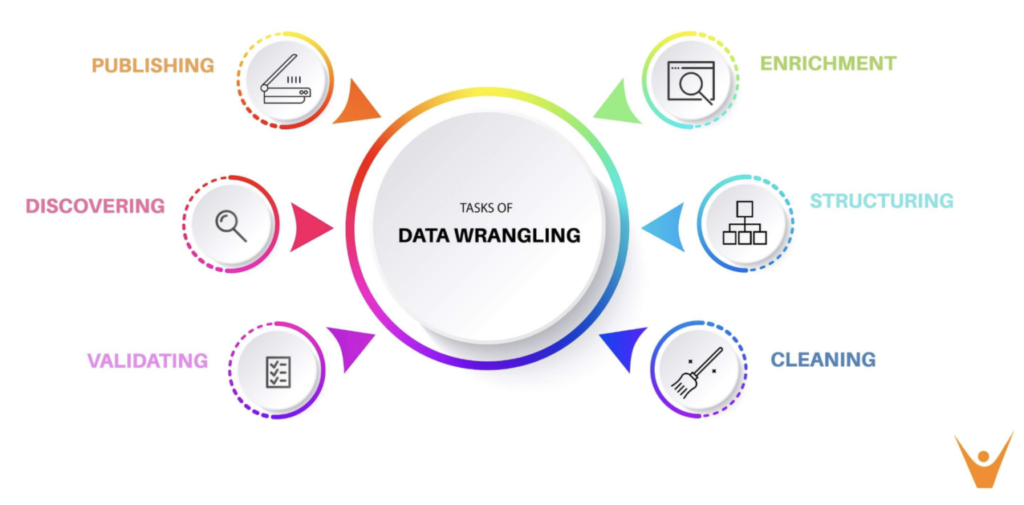
Data Wrangling vs Feature Engineering
In contrast, data scientists interactively adjust data sets using data wrangling in steps 3 and 4 while conducting data analysis and building a model. Data wrangling, also called data munging, discovers, cleans, and validates data, and then structures it for practical use. The process also enriches the content, possibly aggregating the data or transforming it in some cases. Data wrangling can potentially involve dimensionality reduction, standardization, normalization, consolidation of units, or extracting subsets of the data.
Data wrangling and feature engineering are both typically done by data scientists to improve an analytic model or modify the shape of a dataset iteratively until it can reveal deeper insights. Data preparation provides the foundation of data science. It includes feature engineering and data cleansing, which ensures data is of the right quality and form for analysis.
Steps 2, 3 and 4 of the process above can all include feature engineering, which uses domain knowledge to select the optimal attributes for analysis. Feature engineering is inherent to the model building process in step 4, but it also uses data preparation features.
Feature Engineering Examples
One example of feature engineering is how continuous data is handled during the model building and refinement process. Continuous data is the most common type, and it simply means that a value might be any one of many within a range. An age of a person or a temperature on a day are examples of this kind of data.
Here, feature generation mostly relies upon domain data. The possible newly derived features will be limited only by known mathematical operations and available features. For example, a data scientist might choose to group the ages of people in a data set in fixed-width bins, in quantile segments, or in some other way that will best reveal the desired insights.
Another example of feature engineering is based on categorical data, a popular data type where features can take on just one value, or a range of values from a limited set. In this case, a feature is often split into a set of mutually exclusive values. Gender is a good example of this, where the data might be divided like so: unknown, male, female, nonbinary, or other.
Does Explorium Offer Automated Feature Engineering Tools?
Yes. Explorium’s external data platform infuses the slippery art of AI feature engineering with data science and machine learning data augmentation to fuel more powerful insights. Automatically generate thousands of features and focus on tasks that demand domain knowledge and skill. Learn more about Explorium’s data discovery tools, automated feature engineering, and gallery of external data sources.








